
















앙상블(Ensemble)은 '전체적인 어울림이나 통일'을 의미하는데요. 수학에서는 이 앙상블이 많은 수의 입자가 존재하는 경우를 통계적으로 다루는 수학적 방법론을 의미합니다.
이러한 정의의 연장선으로 통계학에서는 앙상블 학습법이라는 용어가 존재합니다.

앙상블 학습법(Ensemble Learning): 분류 분석을 위해 사용되고 있는 방법론으로, 통계학과 기계 학습에서 학습 알고리즘을 따로 쓸 때보다 더 정확한 예측 성능을 얻기 위해 다양한 분류 알고리즘을 사용하여 학습을 진행하는 방법입니다. 단일의 강한 알고리즘 보다 복수의 약한 알고리즘이 더 뛰어날 수 있다는 개념에 기반을 두고 있는 학습법이기도 합니다.

앙상블 학습의 종류?
앙상블 학습의 종류에는 투표기반 분류기인 보팅(Voting), 병렬 결합의 배깅(Bagging), 순차 결합의 부스팅(Boosting) 유형이 있습니다.
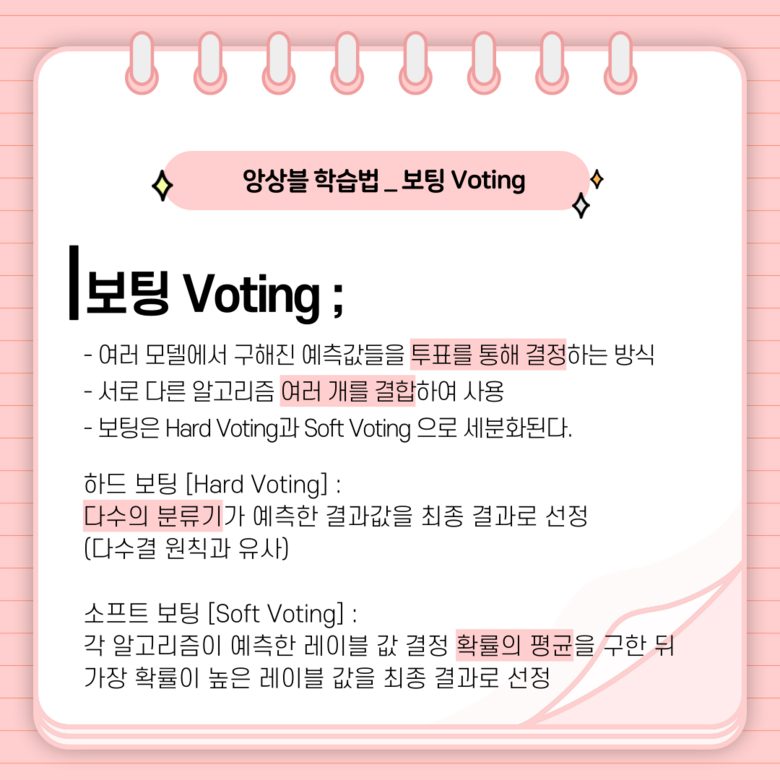
보팅은 다양한 분류 알고리즘으로 구성된 학습 방법이 있을 때, 여러 모델에서 구해진 예측 값들을 투표를 통해 가장 좋은 결과를 결정하는 방식입니다. 서로 다른 알고리즘 여러 개를 결합하여 사용하는 것이 특징입니다.
보팅은 다시 하드보팅(Hard Voting)과 소프트보팅(Soft Voting)으로 나뉘는데요. 하드보팅은 다수의 분류기가 예측한 결과값을 최종 결과로 선정하는 다수결의 원칙과 비슷한 원리를 가지고 있으며 소프트 보팅은 각 알고리즘이 예측한 레이블 값 결정 확률을 예측해, 평균을 구하고 이들 중 가장 확률이 높은 레이블 값을 최종 결과로 선정하는 것입니다.

배깅은 보팅 방식과 다른 데이터 세트를 학습합니다. 배깅은 샘플링으로 추출하는 방식인 부트스트래핑(Bootstrapping) 분할 방식을 거쳐 각 모델을 학습시킨 뒤 결과물을 집계하는 방법입니다. 모두 같은 유형의 알고리즘을 사용하며 배깅의 대표적인 방식으로는 랜덤 포레스트(Random Forest)가 있습니다.
부트스트랩? - 복원추출을 통해 원래 데이터의 수만큼 크기를 같도록 하는 샘플링 방법으로, 하나의 모델에 대하여 데이터를 추출할 경우 중복된 데이터가 있을 수 있다.
복원추출? - 추출한 데이터를 다시 모집단에 복원하여 추출하는 것

부스팅은 예측력이 약한 모형들을 결합하여 강한 예측 모형을 만드는 방법으로, 훈련 오차를 빨리, 쉽게 줄일 수 있다는 장점이 있습니다. 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측하도록 다음 분류기에 가중치를 부여하여 학습과 예측을 진행합니다.
예측 성능이 뛰어나므로 앙상블 학습을 주도하는 방식이며, 대표적인 방법으로는 AdaBoost, GBM, LightGBM 등이 있습니다.
AdaBoost? - Adaptive Boost의 약자로, 약한 학습기의 오류 데이터에 가중치를 부여하며 수행하는 대표적인 알고리즘. 속도나 성능적인 측면에서 decision tree를 약한 학습기로 사용
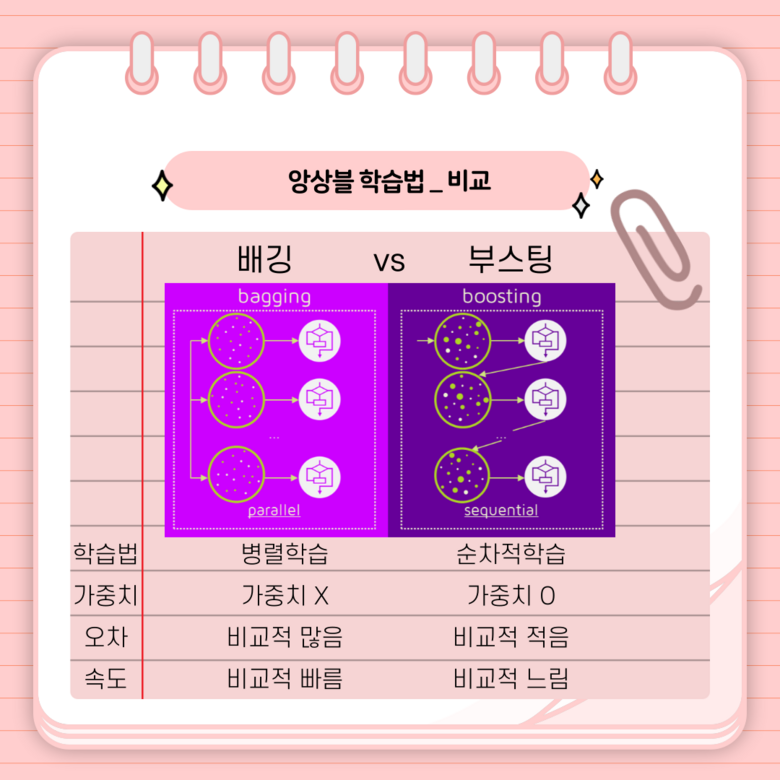
이때, 배깅은 병렬로, 부스팅은 순차적으로 학습하며, 부스팅은 가중치를 부여하지만, 배깅은 그렇지 않다는 차이점이 있습니다.
한번 학습이 끝나면 결과에 따라 가중치를 부여하고, 가중치가 다음 모델의 결과 예측에 영향을 줍니다. 오답에 대해서 높은 가중치를, 정답에 대해서는 낮은 가중치를 부여합니다. 따라서 오답을 정답으로 맞추기 위하여 오답에 더 집중하게 됩니다. 그렇기 때문에 부스팅은 배깅에 비해 에러가 적고 성능이 좋다는 장점이 있지만 순차적으로 학습하기 때문에 속도가 느려진다는 단점이 생깁니다.
각자 방식에 따른 장단점이 존재하기 때문에, 상황에 따른 방식을 선택하여 학습시키는 것이 적합한 방안이 될 수 있습니다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]








![[구혜영 칼럼] 사회복지교육은 미래복지의 나침반이 되어야](/news/data/2026/01/16/p1065596364370517_157_h.png)





