














21세기는 지적 정보화 사회로 과거의 단순히 세분되고 전문적인 것이 아닌 개인의 개성과 창의성을 바탕으로 구성된 정보와 창의적인 아이디어가 중심인 사회이다. 과거의 아날로그 환경과 달리 일상생활에서 PC, 인터넷, 모바일 기기 보급과 함께 데이터가 기하급수적으로 증가하고 있다. 데이터의 규모가 방대하고, 생성 주기도 짧아져 실시간으로 디지털 정보가 폭발적으로 증가한다.
하지만, 의미 없어 보이는 방대한 자료들을 분석해 정제된 데이터를 통해 지금까지 알지 못한 사실을 알아낼 방법이 있다. 바로 ‘빅데이터’ 덕분이다. 빅데이터는 새로운 경제적 가치와 혁신의 원천이자 미래 경쟁력의 우위를 좌우하는 중요한 자원이다.
하버드 비즈니스 리뷰는 데이터 과학자와 관련, "데이터의 홍수 속에서 헤엄치는 사람이다. 복잡한 대량의 데이터를 구조화하면서 분석할 수 있도록 만든다. 데이터 소스를 찾고, 불완전한 데이터를 서로 연결하여, 깔끔한 결과를 보인다"라고 설명했다.
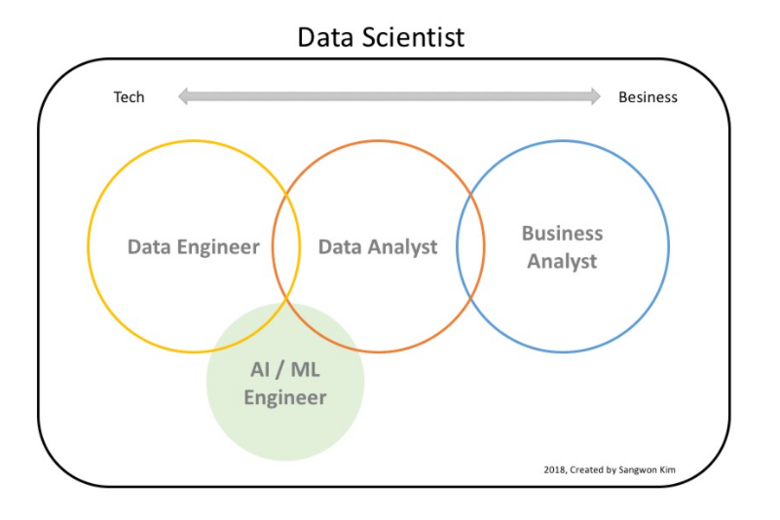
데이터 과학자를 구체적으로 분류하자면 일반적으로 비즈니스 분석가, 데이터 분석가, 데이터 엔지니어, 머신러닝 엔지니어로 나눌 수 있다. 각각의 역할 정의는 기업마다 다르다.
데이터 분석가는 기획자적 성향, 데이터 엔지니어는 개발자적 성향, 데이터 과학자는 연구자적 성향, 머신러닝 엔지니어는 개발자적 성향이 강하다고 볼 수 있다. 각각의 직무에 따른 역할을 아래와 같이 설명한다.
비즈니스 분석가
도메인에 대한 전문성이 높다. 이미 정제된 데이터를 통해 인사이트를 발견하고 의사결정을 할 수 있는 결과물을 만든다. 주로 전략이나 사업 관련 부서에서 근무하며 프로그래밍보다 엑셀과 같은 툴을 주로 사용한다.
데이터 분석가
코딩 기술과 비즈니스 경험, 도메인에 대한 전문성이 필요하다. 데이터를 정제하고 분석할 수 있어야 하며, 머신러닝 등의 기술을 이용해 예측 모델을 만들 수 있어야 한다.
데이터 엔지니어
데이터베이스를 안정적으로 운영할 수 있어야 한다. 데이터를 수집, 가공해 데이터 분석가가 사용하기 쉽게 저장한다. 대용량 데이터에 대해 분산처리 기술을 사용한다. 컴퓨터 공학 쪽 역량이 많이 필요하며 SQL, 유닉스, 리눅스 등에 익숙해야 한다.
머신러닝 엔지니어
자신이 속한 도메인에서 필요한 모델을 개발한다. 개발한 모델을 실제 제품에 적용하고 이를 모니터링하여 성능을 개선한다.
데이터 과학자
보통 R&D 조직에 속하고 논문을 연구한다. 데이터 분석 관련 업무를 한다면 통계 모델링을 수행한다.

데이터 엔지니어와 데이터 사이언티스트는 협업을 한다. 회사에 따라 업무에 대한 배분이 달라진다. 위의 그래프를 보면 고급 프로그래밍, 분산 프로그래밍, 데이터 파이프라인 업무는 비교적 덜 겹치지만 분석, 프로그래밍, 빅데이터는 상당히 겹친다.
기본적으로 자신이 가지고 있는 역량뿐만 아니라 관심 있는 도메인, 강화하고 싶은 역량에 따라 세분화된 직업이 정해질 것으로 보인다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]








![[구혜영 칼럼] 사회복지교육은 미래복지의 나침반이 되어야](/news/data/2026/01/16/p1065596364370517_157_h.png)





