














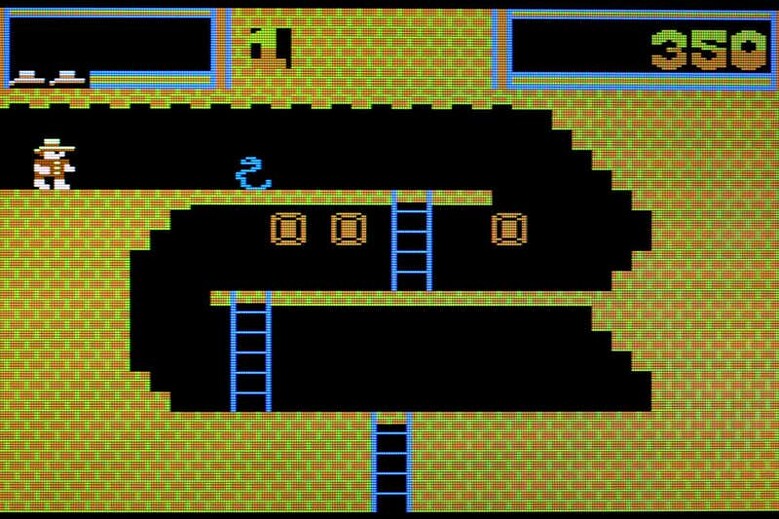
이전의 성공을 기억하고 이를 활용하여 새로운 전략을 수립할 수 있는 인공지능(AI)이 가장 어려운 비디오 게임 중 하나에서 기록적인 높은 점수를 얻었다.
AI 시스템은 강화 학습을 사용한다. 강화 학습은 알고리즘이 각 단계를 수행한 후 특정 목표를 향한 진행에 대해 긍정적이거나 부정적인 피드백을 주어 특정 솔루션을 향하도록 장려한다. 이 기술은 AI 기업 딥마인드가 2016년 세계 챔피언 바둑을 제친 알파고를 훈련하기 위해 사용한 기술이다.
캘리포니아에 있는 우버 AI 랩스(Uber AI Labs)와 오픈AI(OpenAI)에서 근무하는 아드리엔 에코펫(Adrien Ecoffet) 박사와 그의 동료들은 강화 학습 기반 알고리즘이 종종 괜찮은 방법을 우연히 발견하지만, 더 유망한 것을 찾아 다른 영역으로 뛰어들면서 더 나은 해결책을 간과하기도 한다는 가설을 내렸다.
이 문제를 해결하기 위해 그동안 시도했던 다양한 접근 방식을 모두 기억하고 높은 점수를 받았던 순간들로 계속 돌아가는 알고리즘을 만들었다.
에코펫 박사 연구팀의 소프트웨어는 게임을 할 때 화면 캡처를 하여 무엇을 시도했는지를 기억하고, 이를 통해 유사한 모양의 이미지를 그룹화해, 게임의 포인트를 확인한다. 알고리즘의 목적은 점수를 최대화하는 것이며 게임을 다시 할 때마다 새로운 화면 캡처를 하여 이전의 기록을 경신하는 높은 점수에 도달할 때까지 계속 시도한다.
특히 복잡한 게임인 '몬테주마의 리벤지'에서는 강화 학습 소프트웨어의 이전 기록보다 높은 점수를 얻었고, 인간 세계 기록도 능가했다.
일단 알고리즘이 높은 점수에 도달한 후, 연구원은 에뮬레이터로 세이브 상태를 재로드할 필요 없이 뉴럴 네트워크가 전략을 복제하고 게임을 동일한 방식으로 하도록 훈련하기 위해 생각해낸 솔루션을 사용했다. 이 대체 접근 방식은 알고리즘의 뉴럴 네트워크 버전이 각 게임을 해결하는 동안 수십억 개의 화면 캡처를 생성했기 때문에 계산 집약도가 더 높은 것으로 드러났다.
유니버시티칼리지런던의 피터 벤틀리(Peter Bentley) 교수는 강화 학습과 기억의 보관을 결합하는 팀의 접근 방식이 더 복잡한 문제를 해결하는 데 사용될 수 있다고 말했다. 이어, 그는 "이것은 실제적인 향상을 제공하는 것 같은 멋진 새로운 기술 조합이다"라고 평가했다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]








![[구혜영 칼럼] 사회복지교육은 미래복지의 나침반이 되어야](/news/data/2026/01/16/p1065596364370517_157_h.png)





