















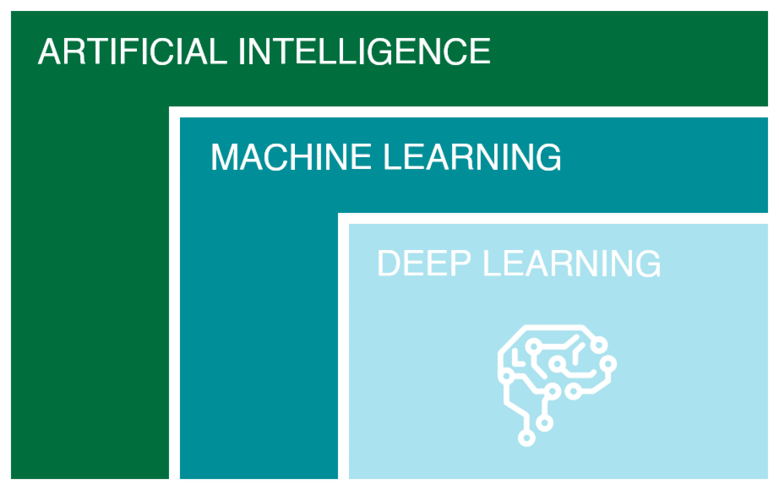
인공지능(AI)
‘지능’이라는 개념을 정확히 설명하기 어렵듯이 ‘인공지능’도 그 뜻을 명확하게 설명하기 어려운 부분이 있다. 사람은 문을 열고 나가는 작은 행동에서도 지능을 사용한다. 이를 자세히 뜯어 보면 손잡이를 잡고 돌리는 어떤 행위가 문을 열어줄 것이라는 경험적인 예측을 통해 행동하는 것을 알 수 있다. 이렇듯 지능은 예측이라는 부분을 어느 정도 포함하고 있다고 그 개념을 이해할 수 있다.
인공지능은 인간의 지능을 컴퓨터로 구현한 매우 넓은 영역으로 볼 수 있으며 간단한 예시로 알파고, 시리 등을 떠올려 볼 수 있다. 학문적으로는 지식기반학습, 기계학습, 딥러닝 등의 범주를 모두 포함하는 가장 큰 영역으로 볼 수 있다.
머신러닝(ML)
ML은 데이터를 입력받아 자동으로 학습되는 컴퓨터 알고리즘을 의미한다. 이는 명확한 용어로 표현 가능한데, 잘 정의된 데이터가 필요하다.
예를 들어, 내일 날씨를 예측하는 시스템을 만든다고 하자. 이때 실제로 당일 날 비가 왔는지 안 왔는지 일주일간의 정확도를 계산하는 성과 P, 다음날 비가 오는 것을 맞추는 목적 T, 학습 데이터로 1년 치의 기상청 데이터를 쓰는 경험치 E로 알고리즘을 정의할 수 있다.
이렇게 정의된 데이터를 적절한 알고리즘에 대입하여 학습결과가 좋으면 우리는 다음날 비가 오는 시스템을 사용할 수 있게 된다.
딥러닝 (DL)
DL은 수많은 ML의 기법 중 한 가지로, 최근에 빅데이터와 고사양 GPU를 사용할 수 있는 환경이 갖춰 짐으로서 좋은 성능을 보이며, 최신 학문으로 자리 잡았다.
인간의 뇌 구조가 작은 뉴런들로 이루어진 것에 착안하여, DL은 작은 정보를 학습하는 뉴런들을 연결해 만든 알고리즘이다. 특히 이미지, 음성 등 인간이 잘 처리하는 자료에 대해 학습 결과가 좋으며 최근 상당수의 AI 기술들은 DL을 사용하고 있다.
DL이 최신기술이라고 해서 ML보다 모든 데이터에 적합하다고 할 수는 없다. 다음과 같은 논점에서 딥러닝을 사용해야 하는지 머신러닝을 사용해야 하는지 판단할 수 있다.
1. 딥러닝은 데이터 사이즈가 아주 클 때 적합하다. 작은 사이즈의 데이터이면서 특히 변수가 작다면, 머신러닝이 적합하다.
2. 딥러닝은 고사양 컴퓨터와 상당한 학습 시간이 필요하다.
3. 데이터에 대한 도메인 지식이 없고, 변수(feature)에 대한 이해가 부족한 경우 변수 가공이 불필요한 딥러닝이 적합하다.
4. 딥러닝은 이미지 분류, 자연어 처리, 음성인식 등의 복잡한 문제에 훌륭한 성능을 자랑한다.
데이터마이닝(DM)
우리는 엄청난 양의 데이터가 매일매일 생성되는 세상에서 살고 있으며, 이로부터 양질의 정보를 획득하는 것이 중요해졌다. 데이터베이스로부터 과거에는 알지 못했지만, 데이터 속에서 유도된 새로운 데이터 모델을 발견하여 미래에 실행 가능한 정보를 추출하고 의사 결정에 이용하는 과정을 데이터마이닝이라고 한다. 즉, 데이터에 숨겨진 패턴과 관계를 찾아내어 광맥을 찾아내듯이 정보를 발견해 내는 것이다.
여기에서 정보 발견이란 데이터에 고급 통계 분석과 모델링 기법을 적용하여 유용한 패턴과 관계를 찾아내는 과정이다. 데이터베이스 마케팅의 핵심 기술이라고 할 수 있다. 카드회사에서 새로운 신용카드를 선보이기 위해 고객 데이터를 사용하는 것, 코로나19 전염성을 파악하기 위해 전 세계 의료 자료를 분석하는 등의 경우가 이에 해당한다. 이때, 많은 양의 데이터를 이해하기 위해서 머신러닝이나 통계 등의 기술을 사용하여 의미 있는 정보를 추출하게 된다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]









![[윤창원 칼럼] 뜨는 도시, 지는 국가 – 지방정부 국제교류의 자율과 책임](/news/data/2025/08/27/p1065597151274916_658_h.png)
![[김대선 칼럼]“사람이 국력입니다”…대통령 직속 ‘자살대책위원회’가 답입니다](/news/data/2025/08/12/p1065607366087447_381_h.png)
![[구혜영 칼럼] 초고령화 사회의 복합위기와 그 준비](/news/data/2025/08/12/p1065606868310300_445_h.png)
![[기고] 박찬대 ‘유감’](/news/data/2025/07/29/p1065571800897621_913_h.png)
![[기고] 내란종식 완수와 개혁·통합을 이끌 여당 대표의 리더십](/news/data/2025/07/28/p1065575493623584_535_h.png)
![[우선희 칼럼] 트럼프 관세, 식탁 물가의 경고음](/news/data/2025/07/28/p1065575183183544_235_h.jpg)




