















책상 위에 하나씩 있는 스탠드 조명이 AI기술을 만나 새롭게 태어났다. 네이버의 ‘클로바 램프(CLOVA LAMP)’는 조명에 자사의 인공지능(AI) 기술을 접목시켜 만든 AI학습 과외선생님이다. 이 AI조명은 아이들의 책을 읽어주고, 모르는 단어를 알려주며 아이들의 호기심 어린 질문에도 척척 답변해 주는 백과사전과 같은 역할을 한다.
책 읽어주는 조명. 상상이나 해보았는가? 상상을 뛰어넘어 현실화 시킬 수 있었던 이 조명에 접목된 기술은 무엇일까? 네이버 AI기술의 집약체 클로바 램프에 적용된 핵심 AI기술 2가지를 알아보았다.
1. CLOVA OCR(Optical character recognition) – CLOVA 광학 문자 인식
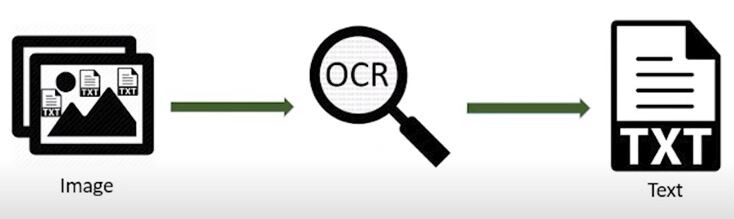
클로바 램프가 조명 아래에 있는 책을 읽는 것은 컴퓨터 비전기술의 일종인 OCR로 인해 실현화 됐다. OCR은 빛을 이용해 손글씨 혹은 인쇄된 활자나 이미지(기호, 마크 등)를 카메라로 인식 후 컴퓨터가 인식할 수 있도록 부호화된 전기신호로 변환하는 기술이다.
OCR 기술의 원리는 다음과 같다. 종이에 조명이 비추고 반사된 반사 광선을 전기 신호로 변환 컴퓨터에 입력을 한다. OCR은 크게 '문자의 위치 추적 기술'과 '문자 판독 기술, '이미지 판독 기술'로 나뉜다. 그리고 최근에는 기술 발달로 문서와 사진 뿐 만 아니라 동영상 속 문자까지 인식할 수 있다.
OCR은 개념은 1929년 독일에서 탄생했고, 이후 미국의 Handel이 문자 인식을 위한 OCR을 제안했다. 1960년대부터 본격적으로 OCR이 주목을 받고 발전하기 시작했다. 처음에는 0 - 9까지의 숫자를 인식하는 불과했지만, 연구를 거듭해 우편 번호와 수표 번호를 인식하는 것을 시작으로 1970년대에는 한자를 포함한 문자와 기호까지 인식할 수 있게 되었다.

OCR 기술은 우리 생활 속에서 많이 쓰이고 있다. 평소에 자주 쓰이는, 신분증이나 카드를 카메라에 비추면 글자를 자동으로 인식하는 기술, 그리고 영수증을 비추면 해당 가게의 위치를 검색해주는 기술이 OCR기반의 기술이다.
OCR 기술이 상업적인 용도로도 많이 쓰이고 있다. 과속 단속 카메라가 찍는 차량의 번호판, 의료보험 회사에 의료비를 청구할 때 환자들이 서류를 사진으로 찍어 보낼 때 등이 있다.
2. NLP(natural language processing) – 자연어 처리

기계인 클로바 램프에 사람인 어린아이가 모르는 것을 질문하면 기계가 이를 이해하고 질문에 대답한다. 그리고 엉뚱한 동문서답이 아닌 원하는 '답'을 말해준다. 어떻게 가능할까?
자연어 처리(NLP)란 기계와 인간이 서로 소통할 수 있도록 그 둘 사이의 상호작용을 돕는 기술이다. 그런데 어떻게 기계가 '오늘 날씨가 어때?'와 같은 사람의 일상언어(자연어)를 이해할 수 있는 것일까? 이는 기계에게 먼저 언어 빅데이터인 말뭉치(Corpus)를 통해 학습시켰기 때문에 가능하다. 따라서 말뭉치가 많아야 AI가 스스로 학습(딥러닝)하며 인간의 언어를 충분히 추론하고 이해할 수 있다.
NLP 기술의 원리는 위의 설명처럼 '말뭉치(Corpus)' 언어 데이터를 통계 기반으로 인식하고 처리하는 기법이다. 따라서 NLP의 수준을 높이기 위해서는 특정목적(어플리케이션 개발, 자연어 처리 연구 등)에 따라 일련의 분석과정을 거쳐 잘 정리된 '말뭉치(Corpus)'가 필요하다. NLP에서는 말뭉치를 품사 단위로 가공해서 데이터로 저장을 하며, 입력으로 들어온 말(자연어)를 해당 데이터에 기반해 텍스트화를 하여 검색을 하는 등 여러가지 작업을 하게 된다.
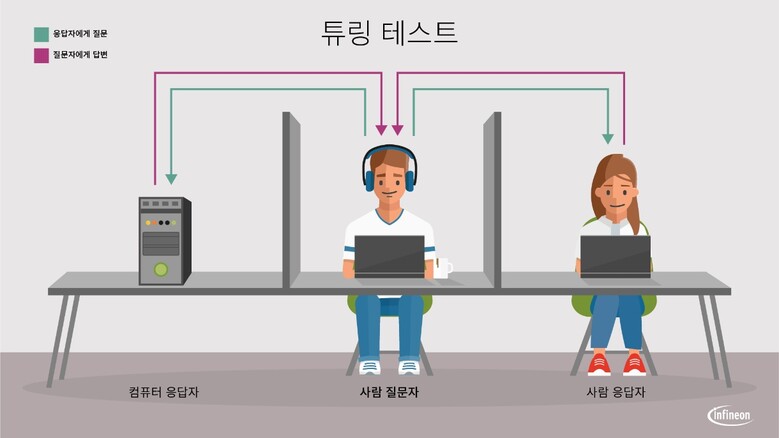
NLP는 1950년에 앨런 튜링 교수이 발표한 '컴퓨터 기계 및 지능' 이라는 제목의 기사와 '튜링 테스트'에서 출발했다. 튜링은 완벽한 AI를 만들고 평가하기 위한 '튜링 테스트'를 제안하였는데, 내용은 즉 슨 '사람과 사람' 그리고 '사람과 AI'가 컴퓨터를 통해 채팅을 해서 사람과 AI의 분간이 어렵다면 '완벽한 AI를 만들었다'는 평가를 내리는 테스트이다. 이후 1980년대부터 머신 러닝이 도입되면서, IBM이 '말뭉치'를 사용한 기계학습을 통해 NLP가 현재까지 비약적으로 발전하게 되었다.
유튜브에서 제공되는 ‘자막 자동 생성’ 기능은 NLP을 기반으로 한다. 영상의 소리가 들리는 동시에 하단에 필요한 언어로 자막이 자동으로 생성되는 기술이며 유저들 사이에서 아주 유용하게 사용된다.
하지만, 한글의 ‘자막 자동 생성’이 타언어에 비해서 정확도가 떨어진다고 느껴본 적이 없는가? AI기술은 항상 빅데이터를 기반으로 기능한다. 자연어처리에서의 빅데이터가 말뭉치인데, 한글은 영어(300억 어절), 일본어(150억 어절), 중국어(300-800억 어절)처럼 보다 대중적인 언어에 비해 말뭉치가 부족하기 때문에 NLP기능이 상대적으로 떨어진다.

그 외에도 클로바 램프는 과학적으로 증명된 빛의 세기와 온도에 기반해, 아이들의 사고력을 위한 조명, 수면을 위한 조명, 독서를 위한 조명 등, 학습 효율을 높여 주기 위한 환경도 조성해줄 수 있다. 또한, 시각 장애인들이 점자에 구애받지 않고 원하는 책을 편하게 독서할 수 있다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]








![[구혜영 칼럼] 사회복지교육은 미래복지의 나침반이 되어야](/news/data/2026/01/16/p1065596364370517_157_h.png)





