














바이두(Baidu)는 지속적인 자연언어 처리를 위한 프레임워크 ERNIE 2.0을 발표했다고 30일(현지시간) Packt가 보도했다. ERNIE는 kNowledge IntEgration을 통한 Enhanced Representation의 약자이다. Baidu는 연구보고서에서 ERNIE 2.0이 BERT와 최근의 XLNet보다 중국어와 영어의 16 가지 NLP 작업에서 우위에 있다고 주장했다. 바이두는 오픈 소스 ERNIE 2.0 모델을 보유하고 있다.
3월에 바이두는 바이두의 심층적인 개방형 플랫폼인 PaddlePaddle을 기반으로한 모델인 ERNIE 1.0 출시를 발표했다. Baidu에 따르면 ERNIE1.0은 모든 중국어 이해 작업에서 BERT보다 성능이 뛰어났다고 밝혔다.
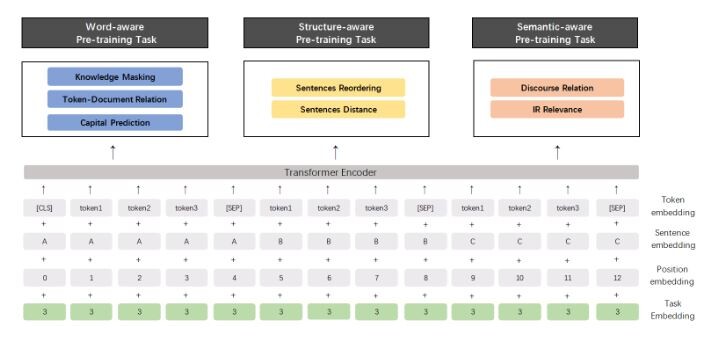
BERT, XLNet 및 ERNIE 1.0과 같은 모델의 사전교육 절차는 주로 단어 또는 문장의 동시 발생을 모델링 하는 몇가지 간단한 작업을 기반으로 하며 문서를 강조 표시한다. 예를 들어 BERT는 양방향 언어 모델작업과 다음 문장예측 작업을 구성하여 단어와 문장의 동시 발생정보를 캡처한다. XLNet은 단어의 동시 발생정보를 포착하기 위해 순열 언어모델 작업을 구성했다.
그러나 동시 발생하는 정보 외에도 교육 자료에는 훨씬 풍부한 어휘, 구문 및 의미가 있다. 예를 들어,사람이름, 장소이름 및 조직이름과 같은 명명된 엔터티에는 개념 정보가 들어 있다. 문장 순서 및 문장 근접정보는 모델이 구조 인식 표현을 학습 할 수있게 해준다. 문서 수준에서의 의미 론적 유사성이나 문장간의 담화 관계는 모델이 의미론적 표현을 학습 할 수 있게 한다.
이 아이디어를 바탕으로 바이두는 언어 이해를 위한 지속적인 사전 교육 프레임워크를 제안했다. 사전 학습 태스크는 지속적으로 다중 태스크 학습을 통해 점진적으로 구축되고 학습 될 수 있다. 바이두에 따르면 이 프레임워크에서 언제든지 서로 다른 사용자정의 작업을 점진적으로 도입 할 수 있으며 이러한 작업은 다중 작업 학습을 통해 수행 되므로 작업 전반에 걸쳐 어휘, 구문 및 의미 정보를 인코딩 할 수 있다. 새로운 작업이 도착할 때마다이 프레임워크는 이전에 훈련된 매개 변수를 잊지 않고 점진적으로 분산 표현을 학습 할 수 있다.
ERNIE는 개발자가 자신의 NLP 모델을 구현할 수 있는 계획을 제공하는 지속적인 사전 교육 프레임워크이다. ERNIE 2.0의 미세 조정 소스코드와 사전 교육된 영어 버전 모델은 깃허브(GitHub)페이지 에서 다운로드 할 수 있다 .
바이두 팀은 ERNIE 2.0 모델의 성능을 영어 데이터세트 GLUE 및 9 개의 인기있는 중국 데이터세트에서 별도로 기존 사전 학습 모델과 비교했다. 결과는 ERNIE 2.0 모델이 7 개의 GLUE 언어 이해 작업에서 BERT 및 XLNet보다 성능이 우수하며 DuReader Machine Reading Comprehension, Sentiment Analysis 및 Question Answering과 같은 9가지 중국어 NLP 작업 모두에서 BERT보다 우수한 것으로 나타났다.
특히, GLUE 데이터 세트의 실험 결과에 따르면 ERNIE 2.0 모델은 기본 모델이든 대형 모델이든 영어 작업에 대한 BERT 및 XLNET보다 거의 종합적으로 뛰어난 성능을 보였다. 또한 연구 보고서는 ERNIE 2.0 대형 모델이 최고의 성능을 달성하고 중국 NLP 작업에 대한 새로운 결과를 창출함을 보여주었다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]
















